Integrating C11-Code Support into Isabelle PIDE
Personnes présentes
- Thibaut Balabonski
- Frédéric Boulanger
- Chantal Keller
- Frédéric Voisin
- Burkhart Wolff
- Lina Ye
Presentators (by order of appearance)
- Frédéric Thuong
Summary:
Use of Isabelle as a generic IDE and the seamless integration of C11 backends into Isabelle document model.
Isabelle as a generic PIDE
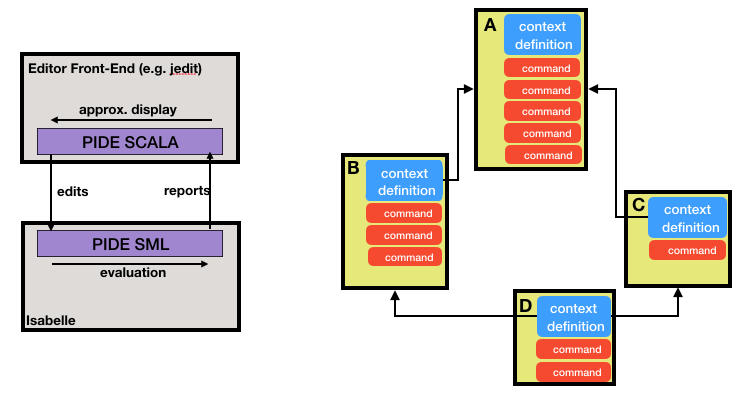
The Isabelle system is based on a generic document model that allows the integration of different backends that work on sub-parts of a document described as a hierarchical, acyclic, graph of files.
The user faces the front-end part of the PIDE and interacts with the document as with any text-editor like jedit. Text editing commands are transmitted to the back-end as "edits" (or "increments" to the document) where they are semantically processed as a collection of light-weight reevaluation threads yielding back an asynchronous stream of "reports" (strings with markups). Those are then handled in the front-end to update the user view of the document. Markups allows to highlight parts of the text but also provides hyperlinks access between objets (relating an occurrence of a variable to its declaration) or implements some navigation links in the internal structure of objects (like for navigation within a term). Outdated "reports" related to modified pieces of text can be dropped without being displayed and re-calculations can be oriented to the current user focus.
In the document below, the Isabelle part re-evaluates theories and interprets commands according to some semantical backends while the SCALA-Jedit part provides basic editing and incremental redisplay of the text.
Using a single, generic, document model that integrates the various views/usages (code, tests, proofs, documentation, etc.) helps traceability of development and modifications in a certification process. It helps to analyse the impact of modifications that have semantical counterparts like modifying the signature of a function or a proof script).
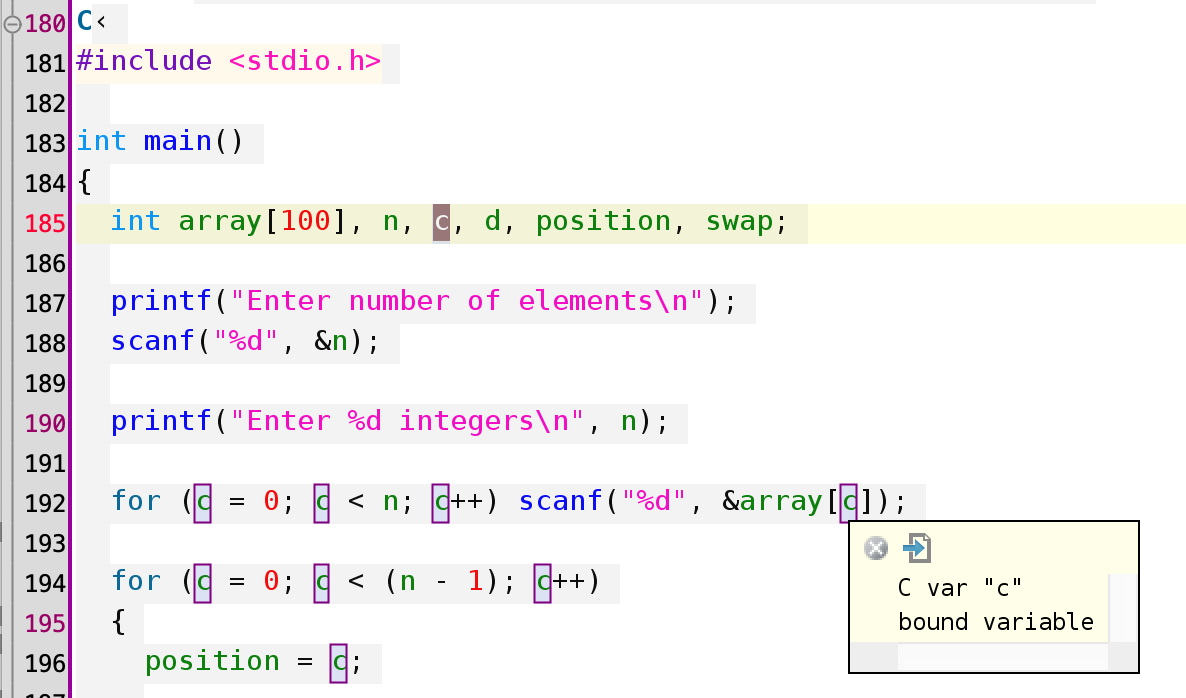
Special "keywords" in the document delimit the sub-parts of the document that must be processed by a tool for a sub-language (ML<...> or C<...> fragment). In the figure below the C<...> keyword delimits some C fragment of code to be processed by some backends.
Backends in the PIDE
The PIDE allows for the integration of various backends that can all have their own semantic model (for instance they do not have to accord on the memory model they assume). Each backend will annotate programs with its specific information such as pre/port-conditions, invariants, ghost-code, etc.
The next file illustrates the use of anti-quotations mechanisms (like C_define), commands and the use of "structured comments" to let each part of the text to be processed by the right tool. Some of the annotations deal with specifying in which context (scope) the command is to be applied, other ones allow to navigate in the syntactic structure of the object at hand: going upwards or downwards in a AST or visiting the elements in a sequence. The focus of an annotation can then be stated and the whole piece of code, for a C program, can be accessed if needed.
Of course each such means to attach a specific processing of document elements must have been registered within Isabelle with its classical extension mechanisms.
The following example shows the use of Isabelle/C with the CLEAN plugin inside. The configuration is done just by loading the Isabelle/C/CLEAN plugin as a theory configuration; the The 4th line configuration command just activates CLEAN and lets it convert the C Front-End syntax in the internal CLEAN monadic representation. The latter is exported by a bunch of definitions.

Similarly, a C source can edited and interpreted in terms of Isabelle/C/AutoCorres. Here, it is an annotation command line 140 inside the source that actually activates AutoCorres interpretation of the C-source:

Similarly to CLEAN, AutoCorres produces a state model (this time: a finer, byte-level machine model) as well as representation of the C code in terms of function definition over the state in some Monad. Actually, AutoCorres represents 2 semantic representations, a low-level and a more abstract one, and proves for the given example the corespondance (which gave AutoCorres its name). These function definitions were stored in the definitions is_prime_def and is_prime'_def which were exported to the Isabelle/HOL environment. There, they are available for the following Hoare-Proof:

Support for the C11 Language and discussion
As a challenging test case for the whole infrastructure, the goal was to support (a realistic subpart of) the C11 language within Isabelle PIDE document model. and to see if it can incorporate the test set of C-code developped for the AutoCorres/seL4 project. The framework must make it possible to add new backends and ways to feed them with annotations provided as specific structured comments.
In particular it includes a C11 parser based upon an existing Haskell LALR-parser generator and C11 library that has been reworked to fit in the Isabelle/PIDE framework.
Part of the talk was devoted to explain the problems associated with the too powerful (and not fully standardized) C11 pre-processor and its processing of include, define and similar "directives". Not every lexical preprocessing can be supported in the framework and the usage of structured comments based on anti-quotations is prefered.
The demo part of the talk illustrated the processing of commands and structured comments and their effects on the text displayed to the user. The stream of LALR Shift/Reduce actions produced during parsing is somehow represented in the AST for the program (in order it can be "replayed" in some sense) and serves as the main way to control the navigation. An intense discussion started about the right way to navigate in such structures. Need the user be aware of such "technicalities" like the exact grammar used for C11, its LALR property or the nature of shit/reduce parsing ? Would a navigation of a specified AST be more natural ? No conclusion for this discussion, besides the fact that everyone agrees on the fact that this navigation must be generic with respect to backends and must clearly defines what is the (sub-)object that is the current focus. For a structured comment, it must be clear to what it applies, and for the user it must be easy to have different granularities for delimiting the object at hand: enlarging or narrowing it.
The architecture of the C11 package is depicted in the file below. Architecture of the C11 package